MininetGym Manual
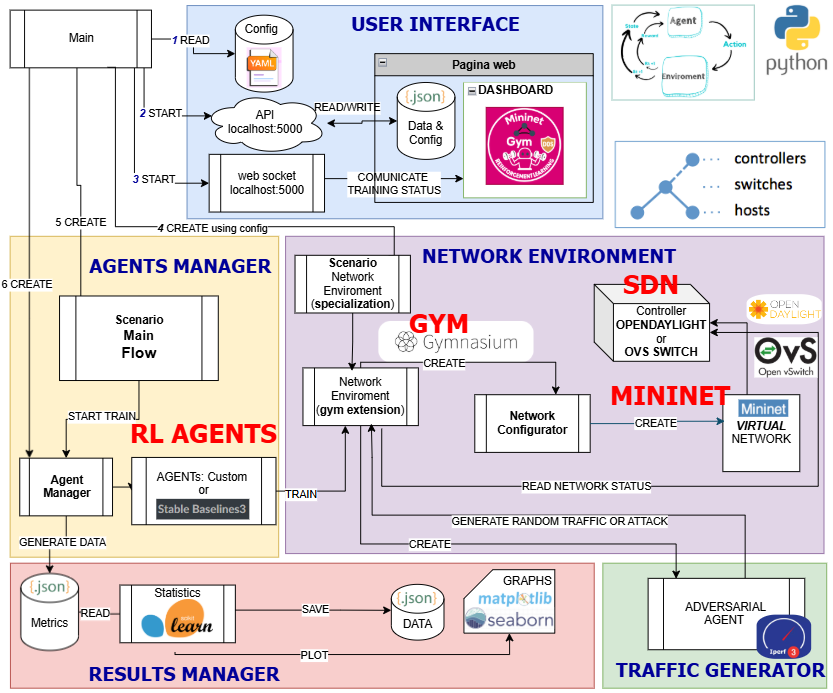
MininetGym is a browser-accessible, open-source framework for training and evaluating Reinforcement Learning (RL) agents on cybersecurity tasks inside a live Software-Defined Network (SDN) emulated with Mininet and controlled by OpenDayLight.
The web dashboard exposes three main panels — Configuration Setup, Training Dashboard, and Results Panel — that cover the full experiment lifecycle without requiring any command-line interaction.
http://<host>:5000 in any modern browser
(Chrome, Firefox, Edge). The UI is fully responsive and works on mobile devices too.
Configuration Setup
This panel lets you define every aspect of an experiment before starting training. Changes are saved immediately with the Save button.
Network Topology
The switch (OVS) sits at the center. All hosts and IoT devices connect to it in a star topology, as shown in the schema below.
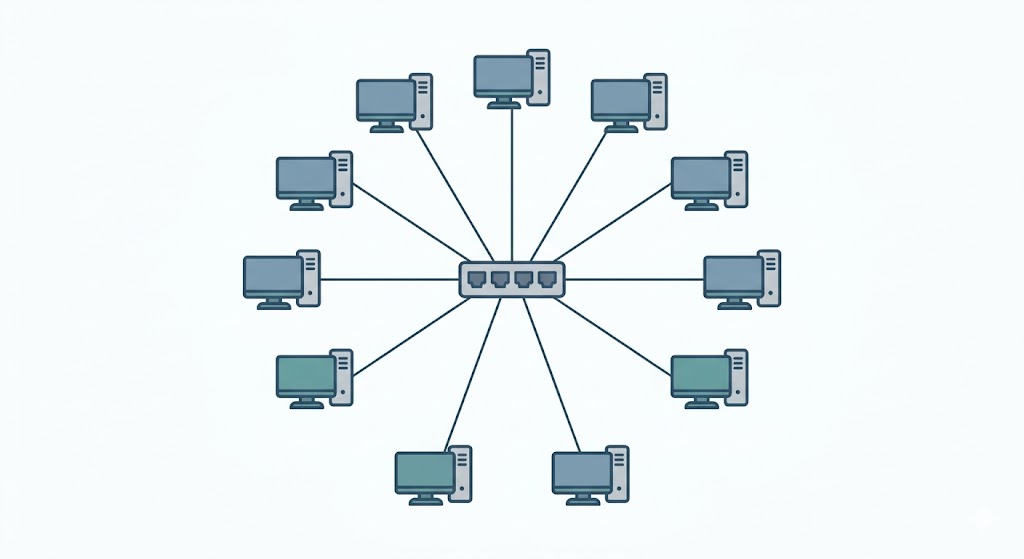
- Hosts — number of regular hosts in the Mininet topology (default 5).
- IoT Devices — number of IoT nodes attached to the switch (default 5).
- Controller — OpenDayLight address; usually
127.0.0.1:8181.
Screenshots — Configuration Panel
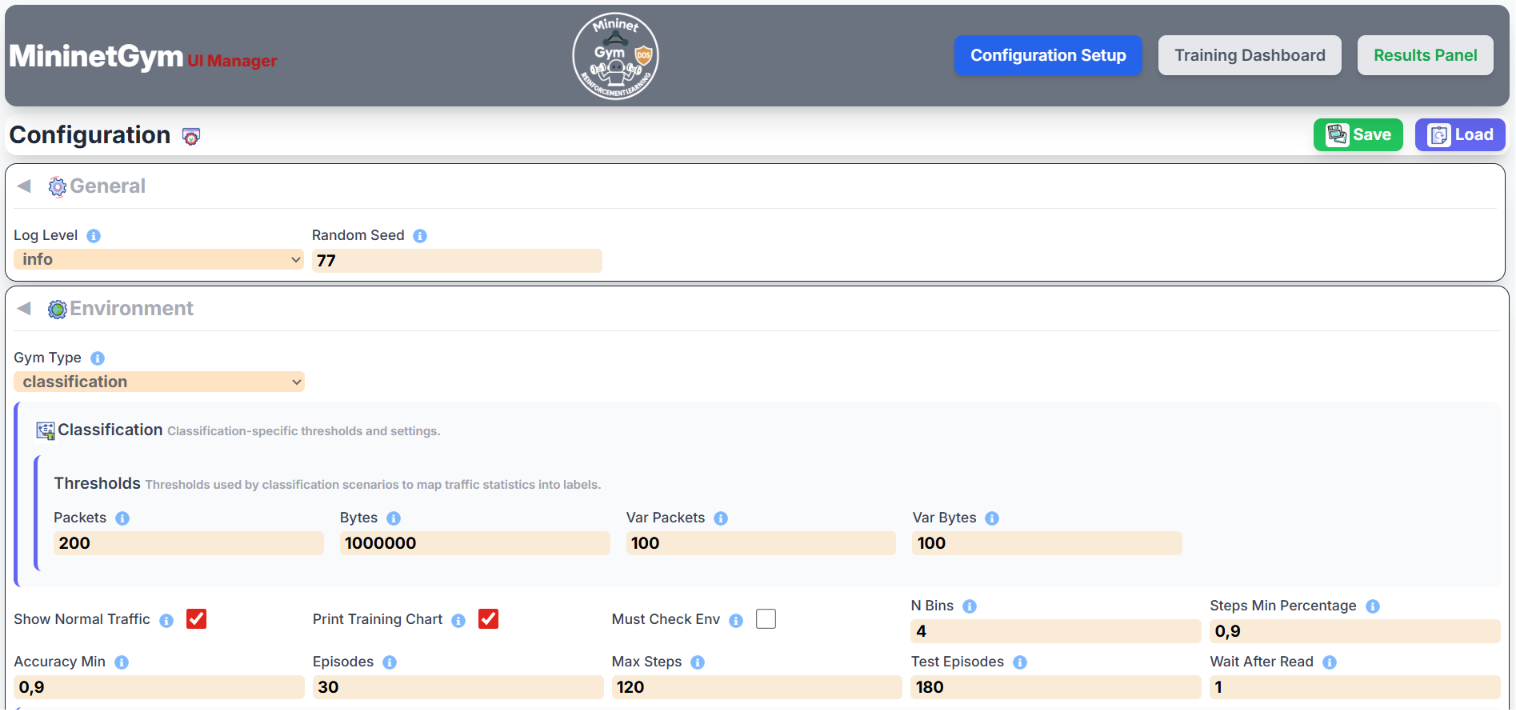
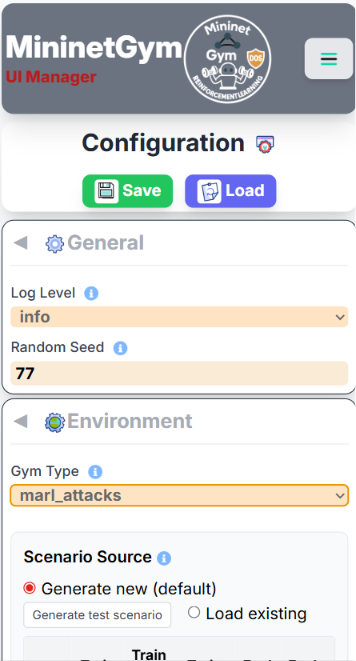
Gym Type (Scenario)
Select the RL environment the agents will train on. Four scenarios are available:
| Scenario | Task | Action |
|---|---|---|
| Classification | Classify traffic: None / Ping / UDP / TCP | Alert only |
| Attack-Net | Binary detection: Normal vs. Attack (global) | Alert only |
| Attack-PerHost | Per-host: Normal / Victim / Attacker | SDN link block |
| MARL | Hierarchical multi-agent (Coordinator + Host agents) | Distributed SDN block |
Agent Configuration
Use the Add Agent button to include one or more agents in the experiment. Each agent entry has:
- Algorithm — choose from Q-Learning, SARSA, DQN, PPO, A2C, Supervised.
- Name — a free-form label shown in all charts and tables.
- Episodes — number of training episodes.
- Steps per episode — maximum steps before an episode resets.
Multiple agents can run sequentially in the same experiment for easy comparison.
Full Configuration Reference
All parameters are stored in config/default.yaml and editable live from the
Configuration panel. The table below documents every key available in the configuration file,
organised by section.
Global Settings
| Parameter | Description |
|---|---|
training_directory | Directory where experiment outputs and training artefacts are stored. |
enable_web_interface | Enable or disable the web UI. |
server_user | Unix user used by the runtime when launching Mininet-related processes. |
log_level | Logging verbosity used by the application. |
random_seed | Seed used to make runs reproducible. |
Environment Parameters (env_params)
| Parameter | Description |
|---|---|
gym_type | Select which scenario pipeline to execute. Use *_from_dataset variants when replaying pre-recorded status JSON files; use non-dataset variants for live/synthetic traffic generation. |
episodes | Number of training episodes. |
max_steps | Maximum number of steps per episode. |
test_episodes | Number of evaluation episodes run after training. |
n_bins | Number of bins used by state discretisation. Higher values preserve more detail but increase the state-space size for tabular agents. |
steps_min_percentage | Minimum fraction of episode steps required before early-stop checks are considered valid. Typical range: 0.7–0.95. |
accuracy_min | Accuracy threshold used by early-stop logic. If reached (with steps_min_percentage satisfied), training can terminate early. |
wait_after_read | Delay (seconds) after reading network counters before the next observation is collected. |
show_normal_traffic | Show normal traffic generation events in the logs and UI. |
print_training_chart | Generate chart images to disk during training. |
must_check_env | Enable extra Gymnasium environment validity checks before running. |
- Generate new (default) — a new scenario is created when training starts.
- Generate test scenario — creates a preview in memory and opens the analysis popup; no file is saved.
- Load existing — click a row to select an existing
scenario.json. When navigating to Training,episodes,max_stepsandtest_episodesare overridden with the values stored in that file.
Attack Parameters (env_params.attacks)
Active only for attack-oriented scenarios: Attack-Net, Attack-PerHost, MARL.
| Parameter | Description |
|---|---|
likely | Base probability that a host starts an attack when idle. Can evolve dynamically during generation depending on scenario logic. |
likely_train | Attack likelihood during training episodes (Attack-PerHost only). Range: 0.0–1.0. Higher values create frequent attacks for policy learning. |
likely_eval | Attack likelihood during evaluation episodes (Attack-PerHost only). Range: 0.0–1.0. Lower values simulate realistic sparse attack conditions. |
max_attack_percentage | Upper cap for effective attack probability (0.0–1.0). Example: 0.9 means attack likelihood scales up to 90% in high-pressure phases. |
short_attack_duration | Duration (steps) of SHORT_ATTACK windows. Lower values create bursty spikes; higher values create sustained micro-attacks. |
long_attack_duration | Duration (steps) of LONG_ATTACK windows. Increase for persistent attacks; reduce for more fragmented behaviour. |
no_attack_timeout | Cooldown (steps) after an attack before the same host can attack again. Lower values increase attack density. |
unblock_min_hold_rounds | Minimum full rounds to keep a host blocked before allowing unblock. |
unblock_required_normal_streak | Consecutive NORMAL decisions required while blocked before the host is unblocked. |
apply_drop_rules | If true, the environment applies OpenDayLight drop rules when the agent takes the block action. If false, the environment provides reward feedback only without modifying network traffic. |
Detection Thresholds
Thresholds used by rule-based labelling in both attack and classification scenarios.
| Parameter | Applies to | Description |
|---|---|---|
attacks.thresholds.packets | Attack scenarios | Absolute packet-count threshold. Values above this are treated as anomalous. |
attacks.thresholds.var_packets | Attack scenarios | Allowed packet variation (%) versus baseline. Above this delta, traffic may be flagged as unstable. |
attacks.thresholds.bytes | Attack scenarios | Absolute byte-volume threshold used with packet thresholds to characterise attack intensity. |
attacks.thresholds.var_bytes | Attack scenarios | Allowed byte variation (%) versus baseline. Useful for volumetric anomaly detection. |
classification.thresholds.packets | Classification | Packet threshold for traffic class labelling. |
classification.thresholds.bytes | Classification | Byte threshold for traffic class labelling. |
classification.thresholds.var_packets | Classification | Allowed packet variation percentage for classification. |
classification.thresholds.var_bytes | Classification | Allowed byte variation percentage for classification. |
Network Topology (env_params.net_params)
| Parameter | Description |
|---|---|
num_hosts | Number of regular hosts in the simulated network. |
num_switches | Number of OVS switches in the simulated network. |
num_iot | Number of IoT nodes in the simulated network. |
traffic_types | Allowed normal-traffic generators. Common set: none, ping, udp, tcp. |
start_cli | Open the Mininet CLI after creating the network (useful for manual inspection). |
SDN Controller (env_params.net_params.controller)
| Parameter | Description |
|---|---|
ip | Controller IP address (e.g. 127.0.0.1 or Docker host IP). |
port | Controller TCP port (default 8181 for OpenDayLight REST API). |
usr | Controller username (default admin). |
pwd | Controller password. |
Agent Common Parameters (agents.*)
Each entry in the agents list represents one agent configuration. Multiple agents can be enabled in the same run.
| Parameter | Description |
|---|---|
name | Display name shown in charts, tables and PDF exports. |
algorithm | Algorithm identifier: q_learning, sarsa, dqn, ppo, a2c, supervised. |
enabled | Enable or disable this agent without removing its configuration. |
progress_bar | Show a progress bar in the terminal while training this agent. |
skip_learn | Skip learning and use the agent for evaluation or inspection only. |
show_action | Log the chosen action at every step (verbose). |
load | If true, attempt to load saved weights/artefacts before training. |
load_dir | Relative path (from training root) to a saved run folder. Must contain artefacts compatible with the selected algorithm. |
save | Save the trained model artefacts at the end of the run. |
state_input_mode | Input representation for deep agents: normalized (recommended) or raw. Keep consistent when loading checkpoints. |
net_arch | Neural network architecture list for deep agents (e.g. [64, 64]). |
Algorithm-Specific Hyperparameters
Q-Learning & SARSA
| Parameter | Description |
|---|---|
learning_rate | Step size for Q-table updates. |
discount_factor | γ — how much future rewards are discounted (0–1). |
exploration_rate | Initial ε for ε-greedy exploration. |
exploration_decay | Multiplicative factor applied to ε after each episode. |
DQN (Deep Q-Network)
| Parameter | Description |
|---|---|
learning_rate | Adam optimiser learning rate. |
gamma | Discount factor for future rewards. |
buffer_size | Capacity of the experience replay buffer. |
batch_size | Mini-batch size drawn from the replay buffer per gradient update. |
target_update_interval | Number of steps between target network weight copies. |
learning_starts | Number of environment steps collected before learning begins. |
exploration_fraction | Fraction of total training steps over which ε is annealed. |
exploration_initial_eps | Starting value of ε. |
exploration_final_eps | Final (minimum) value of ε. |
PPO & A2C
| Parameter | Description |
|---|---|
learning_rate | Adam optimiser learning rate. |
gamma | Discount factor for future rewards. |
n_steps | Number of rollout steps collected before each policy update. Must satisfy batch_size < n_steps × n_envs. |
batch_size | Mini-batch size used for gradient updates (PPO only). |
ent_coef | Entropy coefficient — higher values encourage exploration; lower values promote exploitation. |
batch_size must be strictly less than
n_steps × n_envs. Violating this causes a Stable-Baselines3 assertion error at startup.
Training Dashboard
Start the experiment from the Configuration panel and switch to Training Dashboard to monitor progress in real time. All data is pushed via WebSocket (Socket.IO) — no page refresh needed.
Screenshots — Training in Action
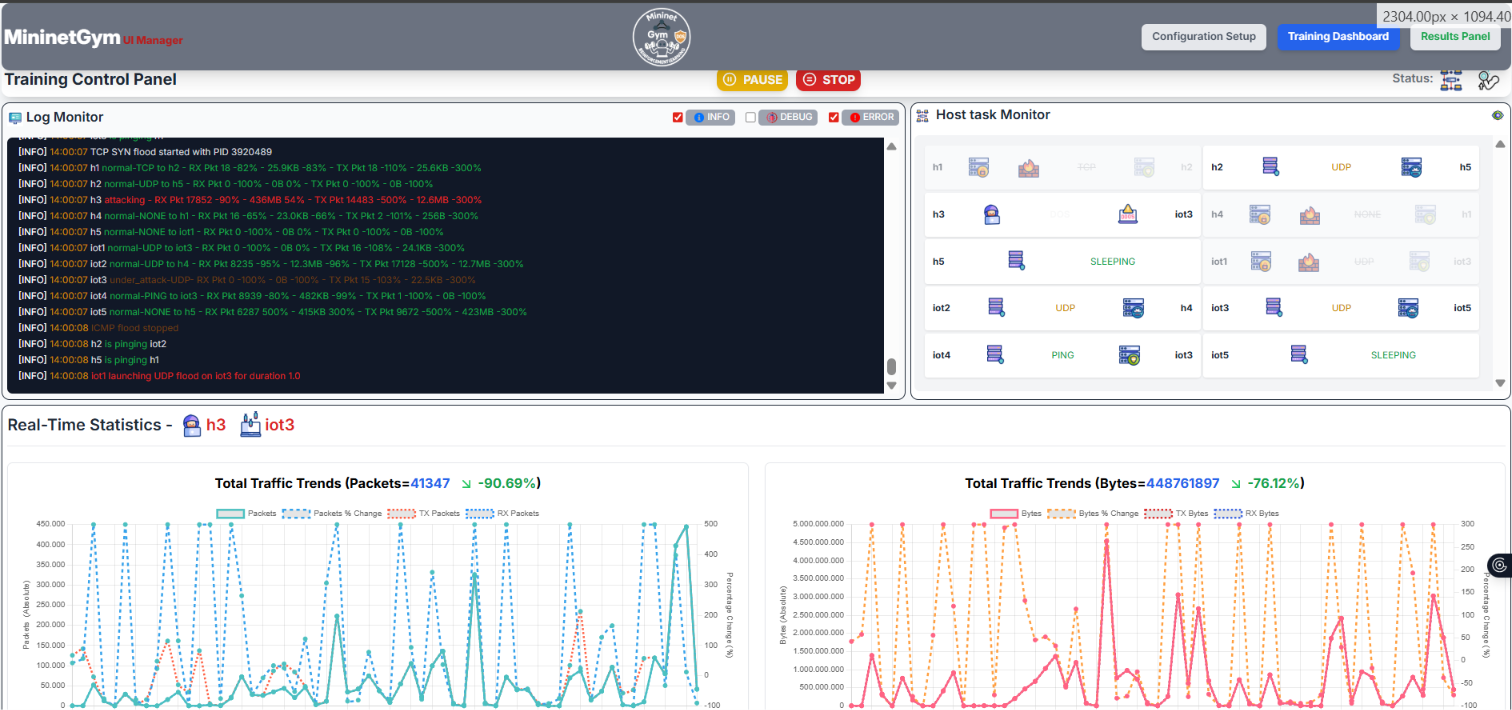
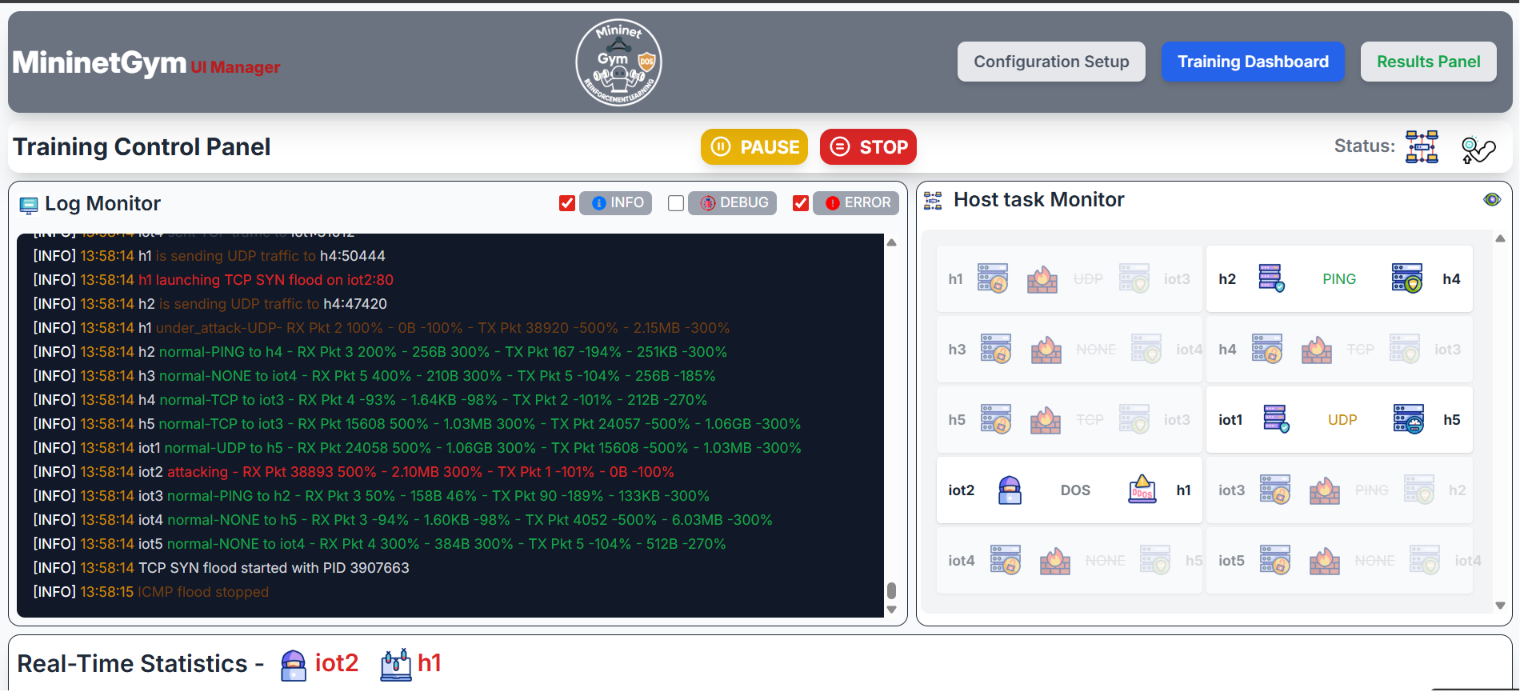
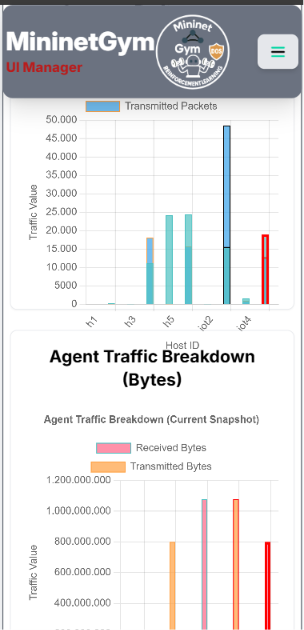
Live Charts
- Reward per Episode — cumulative reward obtained by the agent in each episode.
- Accuracy per Episode — percentage of correct classifications over the episode.
- ε (Epsilon) Decay — shows how exploration decreases over time (tabular / DQN).
Host Status Monitor
A live grid shows the current classification label for every host: Normal, Attacker, or Victim. When an SDN block is issued, the attacker cell displays a lock icon.
Controls
- Pause / Resume — suspends the training thread; the network keeps running.
- Stop — terminates the current experiment and saves partial results.
Results Panel
After training completes (or is stopped), switch to the Results Panel to inspect per-agent metrics and export a PDF report.
Screenshots — Results Panel
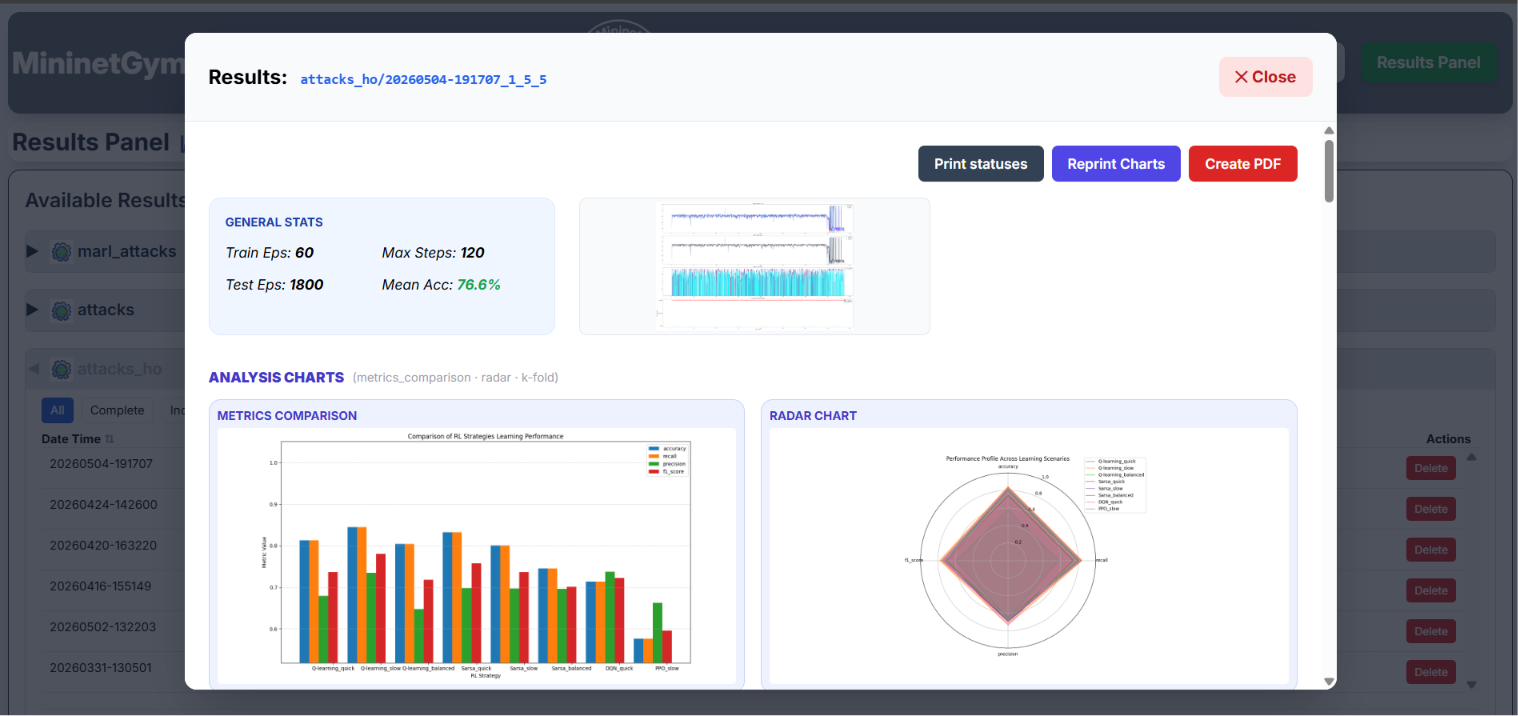
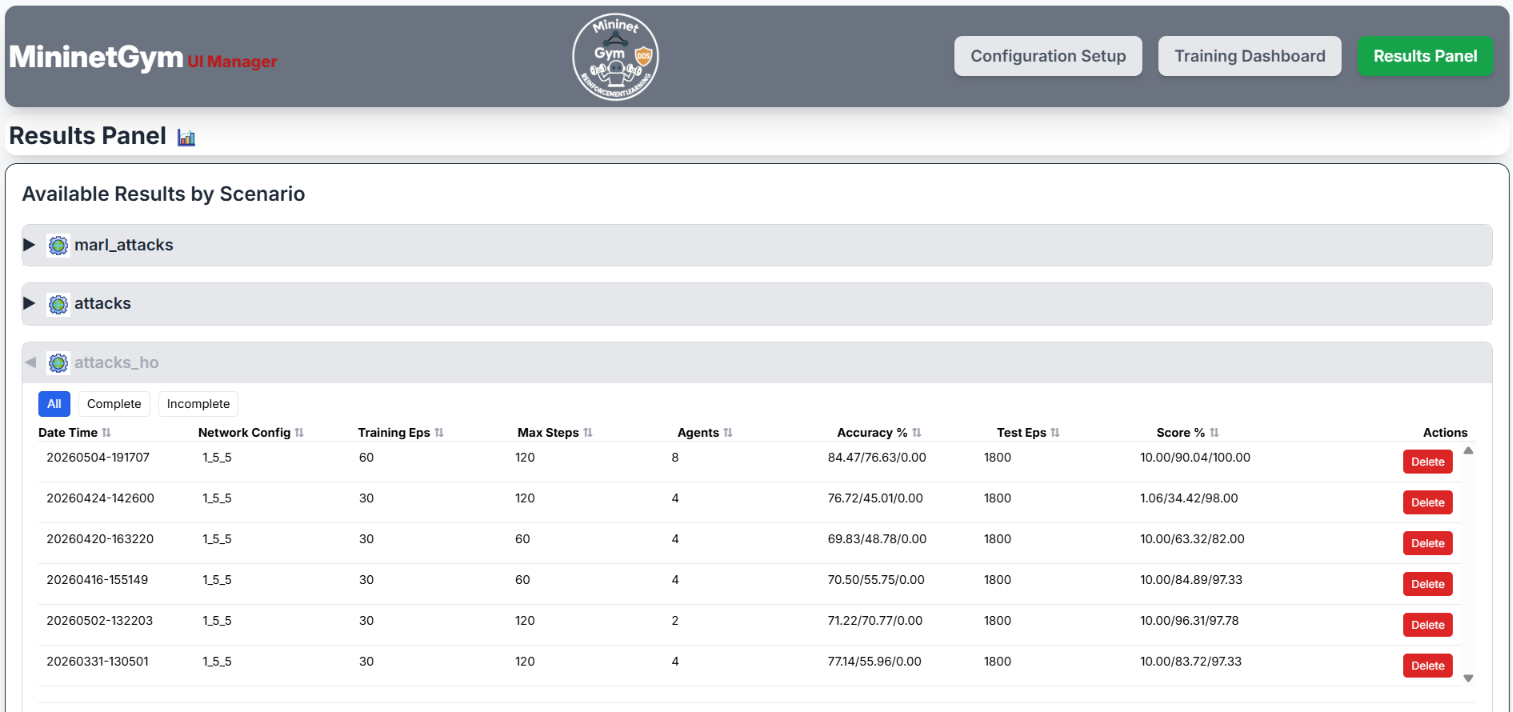
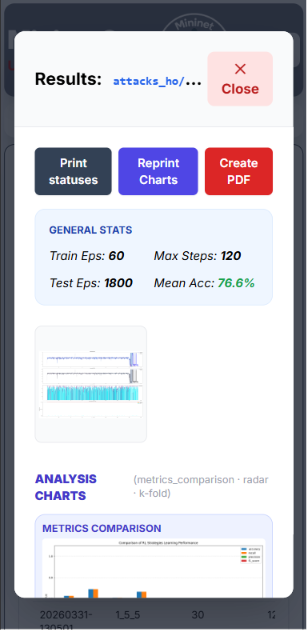
Metrics Summary Table
For each agent the table shows:
- Accuracy, Precision, Recall, F1-score
- Mitigation Ratio — SDN blocks issued / total attack events detected.
- False Negative Rate (FNR) — missed attacks; penalised ×2 in the reward function.
- Attack Latency — average steps from attack start to SDN block.
Comparison Charts
- Bar chart — side-by-side accuracy / F1 across all agents.
- Radar chart — multi-dimensional agent profile (accuracy, precision, recall, FNR, mitigation).
- Confusion Matrix — per-agent heatmap of predicted vs. true labels.
PDF Export
Click Export PDF to download a formatted report containing all charts, the metrics table, and the experiment configuration.
Supported RL Agents
Q-Learning
Tabular off-policy TD method. The observation space is log-bin discretized to keep the state table manageable. Best suited for low-dimensional scenarios (Classification, Attack-Net).
SARSA
On-policy variant of Q-Learning. Uses the action actually taken (rather than the greedy action) for the TD update, making it slightly more conservative in exploration.
DQN — Deep Q-Network
Uses a neural network to approximate the Q-function. Includes an experience replay buffer and a target network. Implemented via Stable-Baselines3.
PPO — Proximal Policy Optimization
Actor-critic on-policy algorithm with a clipped surrogate objective. Robust and sample-efficient; generally the best baseline for continuous or large discrete observation spaces.
A2C — Advantage Actor-Critic
Synchronous on-policy actor-critic. Faster per-step than PPO but may require more episodes to converge. Good for quick experiments.
Supervised Agent
A classification baseline trained with supervised learning on labelled traffic data. Supports incremental learning: the model is updated after each episode with the new observations collected during training. Used as a performance ceiling reference.
Attack Scenarios
The Attack Generator runs on dedicated Mininet hosts and can produce:
- UDP Flood — high-rate UDP packets toward a victim host.
- TCP Flood — repeated TCP connection attempts.
- ICMP Flood — continuous ping storm.
- SYN Flood — half-open TCP connections to exhaust victim resources.
- Slowloris — slow HTTP attack that holds connections open.
Attacks are injected randomly during training so that agents learn to detect and mitigate them across varying conditions.
MARL — Multi-Agent Mode
In the MARL scenario, two agent types collaborate via an internal message bus:
- Coordinator — observes global network statistics (ℝ5), decides whether to signal an alert to host agents.
- Host Agents (one per host) — observe per-host traffic (ℝ9), take local block / no-block actions.
All agents run in parallel threads. The coordinator's signal is included as an extra feature in each host agent's observation vector.
Tips & Troubleshooting
Training does not start
- Make sure the Mininet topology is running (
sudo python main.py). - Check that OpenDayLight is reachable at the configured address.
- Verify no previous experiment is still running (use Stop first).
Charts are not updating
- Confirm the browser has an active WebSocket connection (look for the green dot in the status bar).
- Reload the page — the Socket.IO client will reconnect automatically.
SDN blocks are never triggered
- Only the Attack-PerHost and MARL scenarios issue SDN drop rules.
- Make sure OpenDayLight credentials are correct in the config.
Low accuracy after many episodes
- Increase
episodesor lowerlearning_ratefor slower but more stable convergence. - For tabular agents (Q-Learning / SARSA) try increasing
epsilon_decayto explore longer. - PPO / A2C may need more
n_stepsfor complex scenarios.
PDF export fails
- Ensure wkhtmltopdf or WeasyPrint is installed on the server.
- Check server logs (
app.log) for the detailed error.
Keyboard & UI Shortcuts
| Action | How |
|---|---|
| Close this manual | Press Esc or click outside the panel |
| Navigate sections | Click any entry in the left Contents sidebar |
| Switch panel | Header navigation buttons (Configuration / Training / Results) |
| Mobile menu | Tap the ☰ button in the top-right corner |
About
MininetGym is developed at DISMI — University of Modena and Reggio Emilia by Salvo Finistrella, Stefano Mariani, and Franco Zambonelli.
Source code: github.com/dipi-unimore/mininet-gym
Contact: salvo.finistrella@unimore.it
Paper: ScienceDirect — doi.org/10.1016/j.simpa.2025…